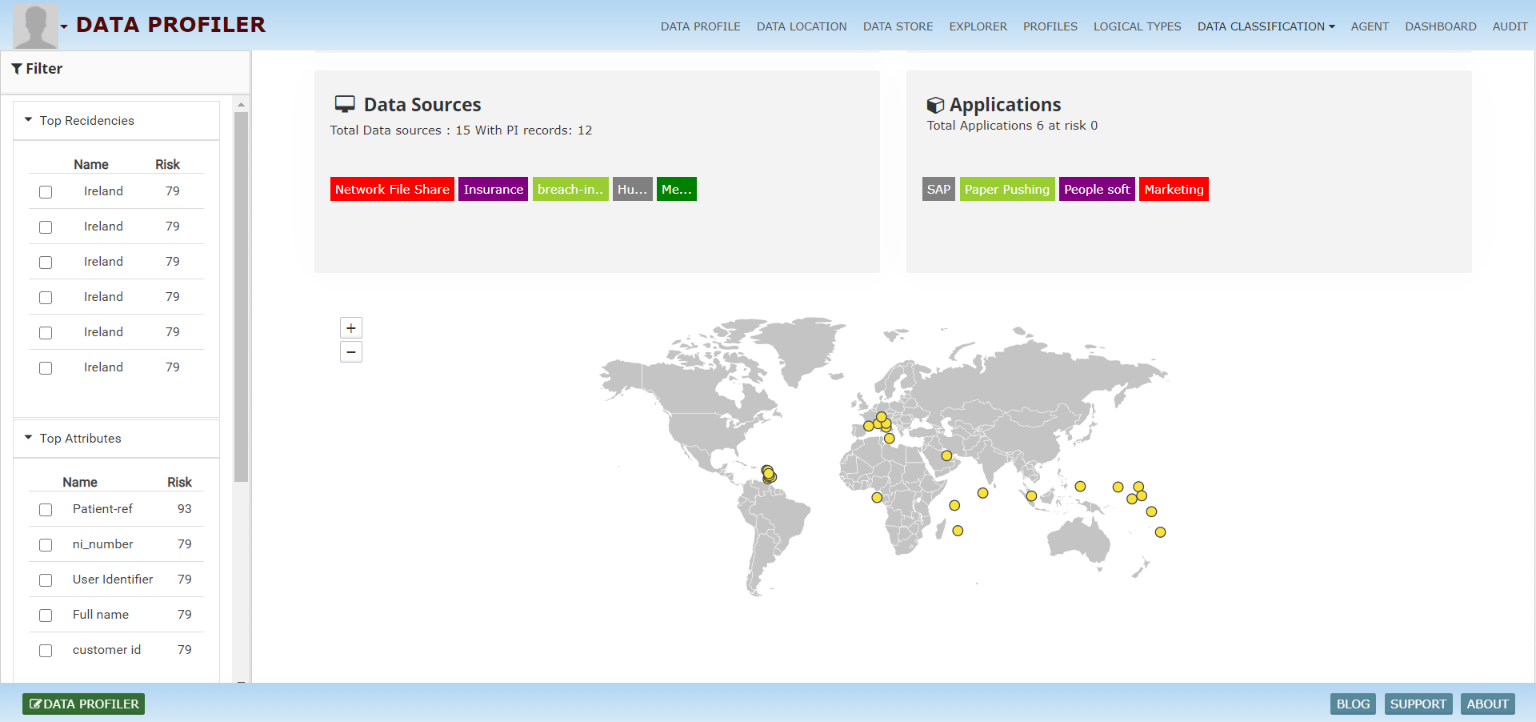
Companies are storing lots of data and having a clear visibility of this data at the enterprise level makes the business efficient, safe and complaint. Manual profiling/classification of the data is very costly and time consuming. InsightLake solution enables the companies to perform the data classification using an intelligent, flexible and robust framework, which uses variety of data elemenets, glossaries, metadata coupled with business rules and ML models.
Classification manager is a central core engine, which provides following functionality:
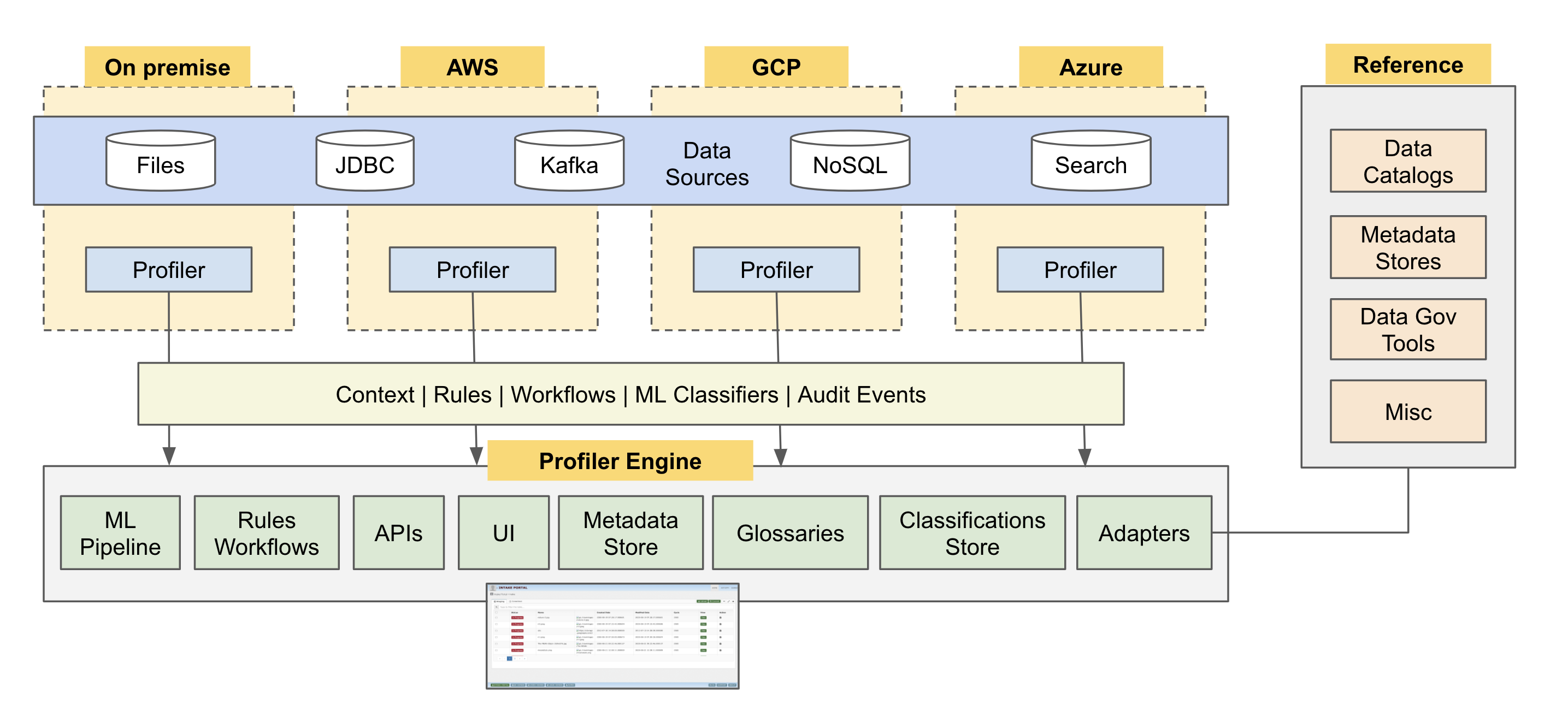
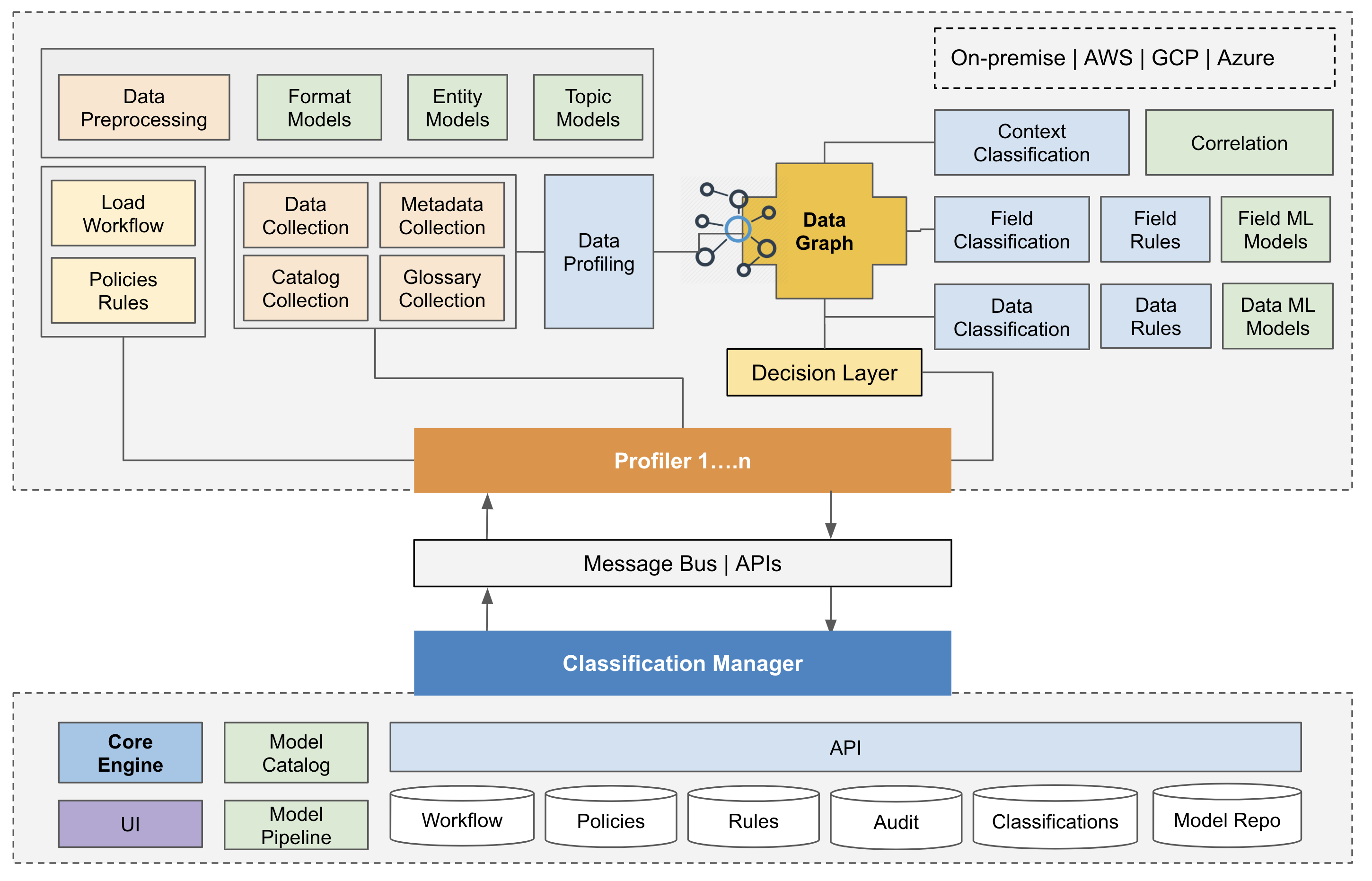
Diagram shows the high level architecture of the profiler. Multiple instances of profilers can be deployed on-premise or cloud environments and they connect to the centralized classification manager.
InsightLake Data Profiler Big Data based solution enables companies to perform following operations to create reliable data in both real time & batch pipelines.
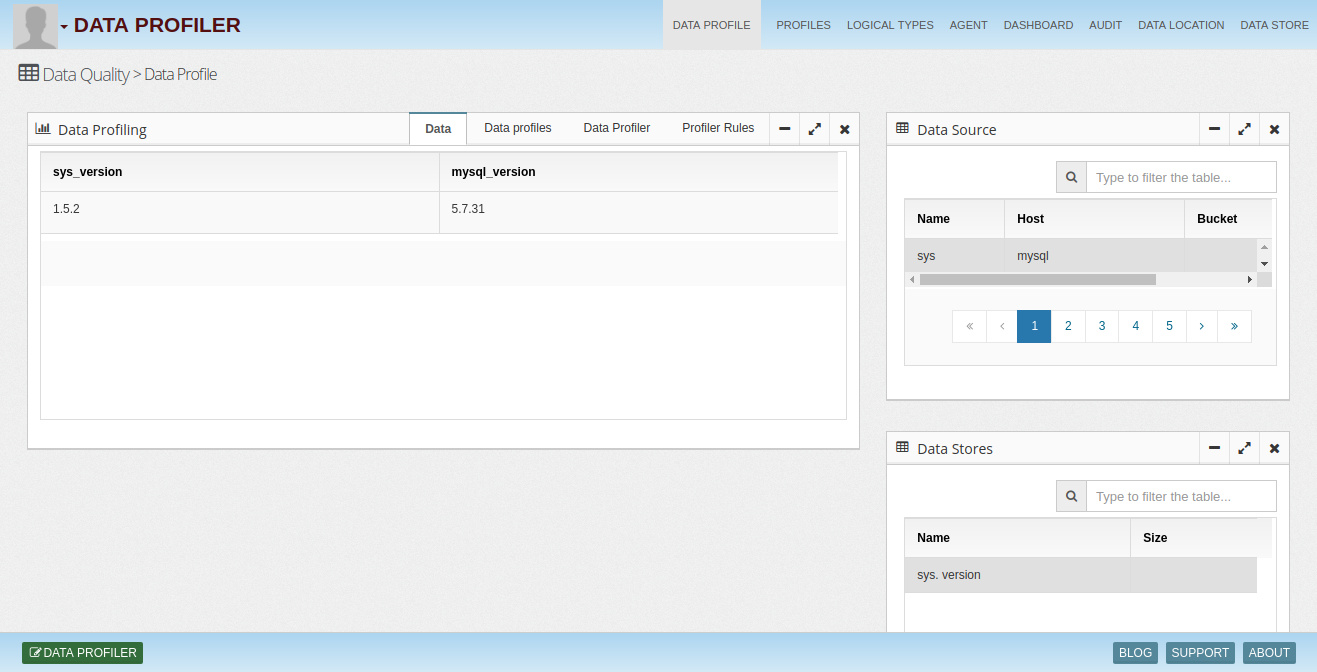
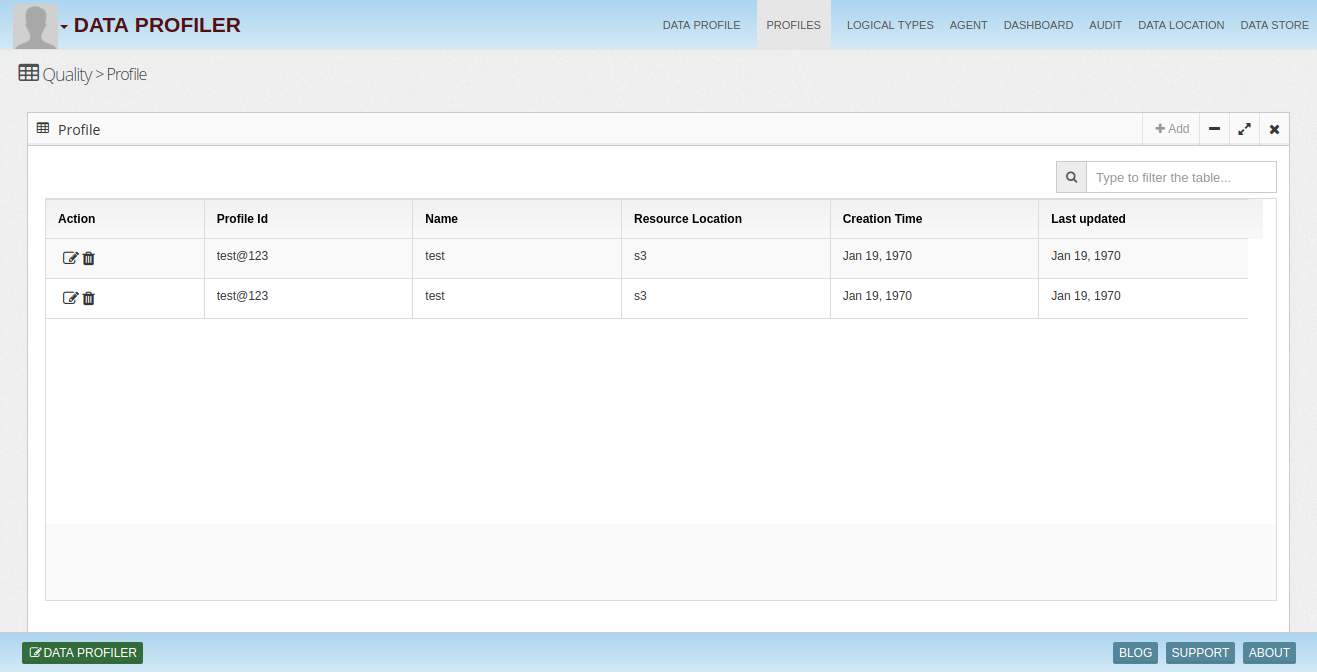
Context to store rules
Organizations build clean data sets, which they call data marts, subject areas etc. These data sets get data from various data sources. Data from different sources can come in different formats and with quality issues. These in-consistent data elements can be standardized using quality rules in quality center easily with rich function library.
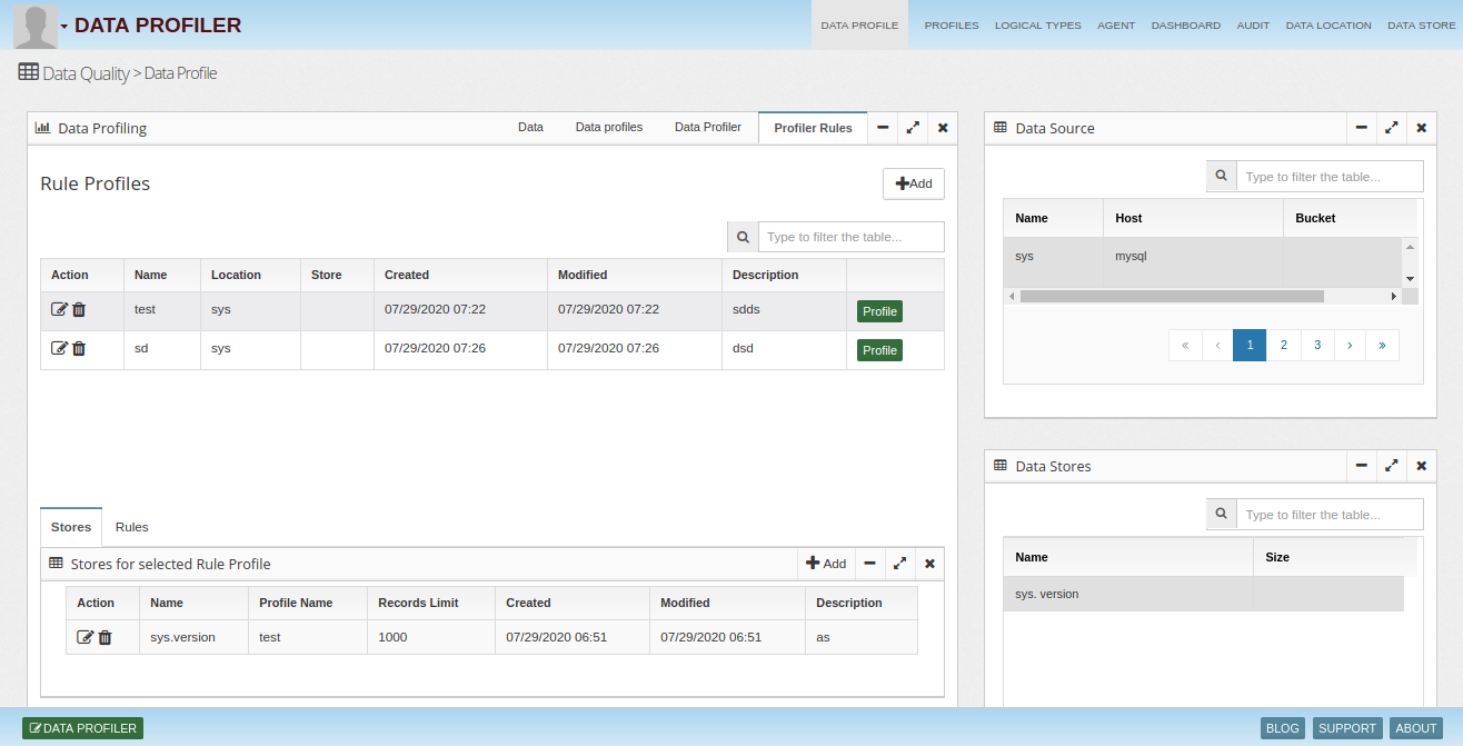
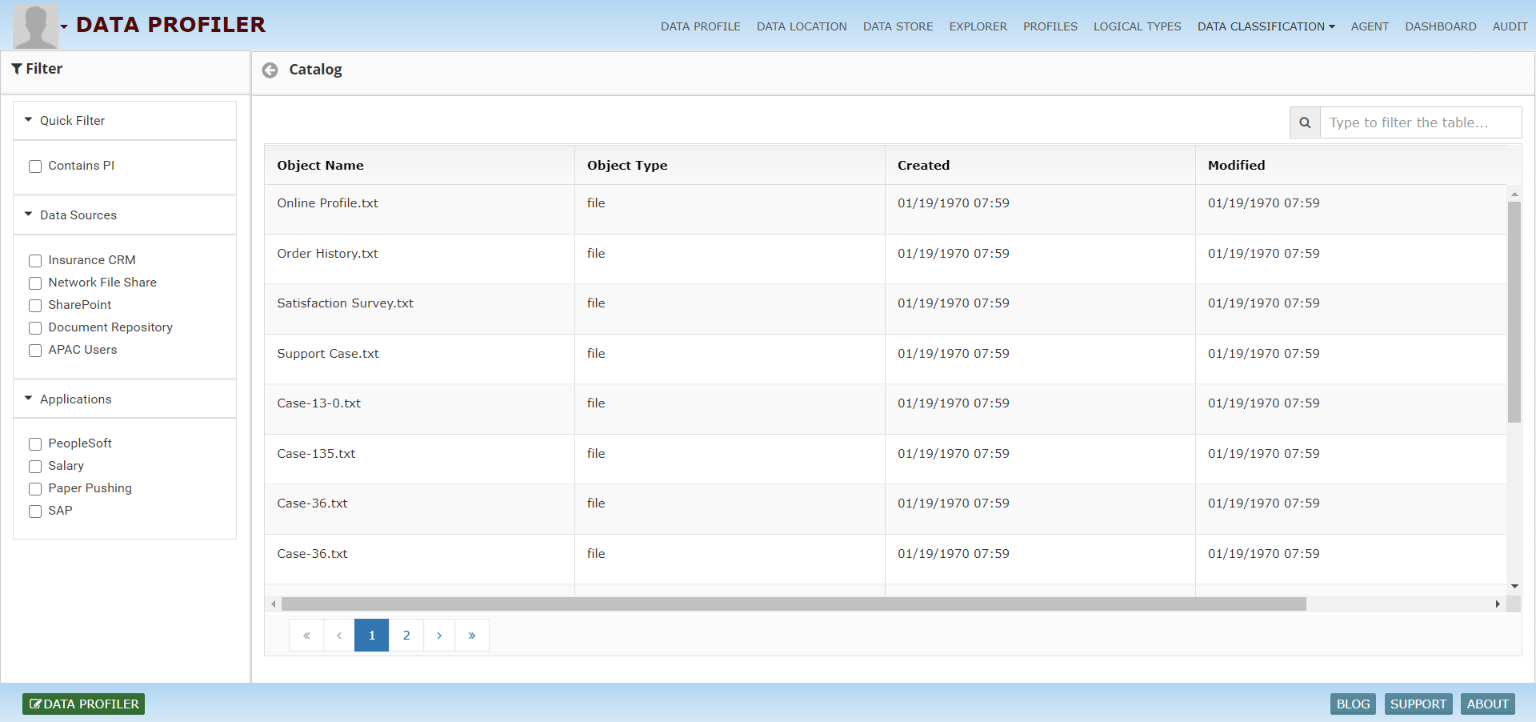
Automatically catalog and map sensitive & personal data with deep data insight, incorporating active metadata and classification. Gain additional privacy, security, and business insight – all within a single pane of glass.
Automate classification at scale for large data volumes, uncover duplicate, derivative and similar data, and rapidly deliver meaningful insight with InsightLake cluster analysis.
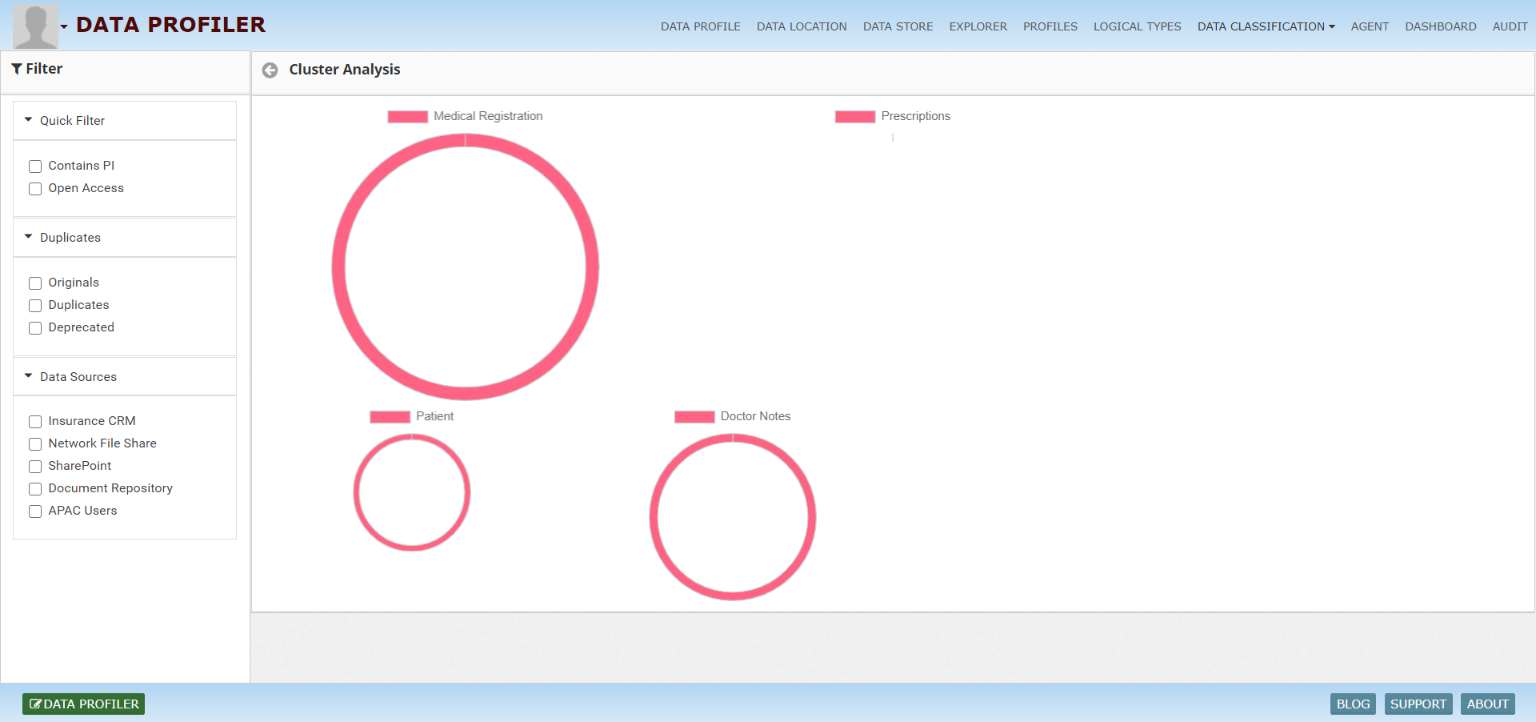
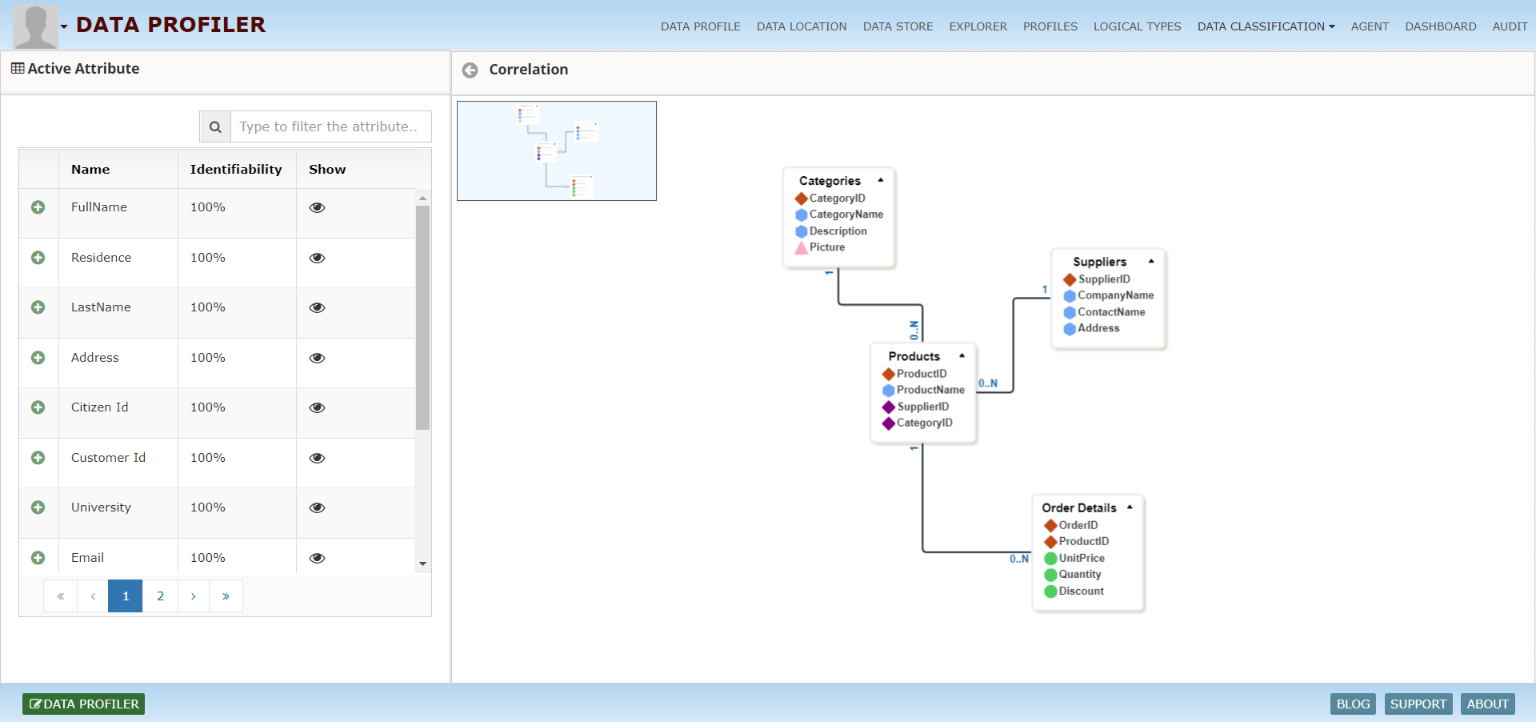
Add context to classification and surface relationships between data points. Build identity and entity profiles, associate whose data it is, and visualize how data is interconnected across data sources.
Classify all types of data across data stores and in the cloud: discover sensitive and personal data, analyze activity, meet compliance, and protect personal and sensitive data – all with a data-centric approach.
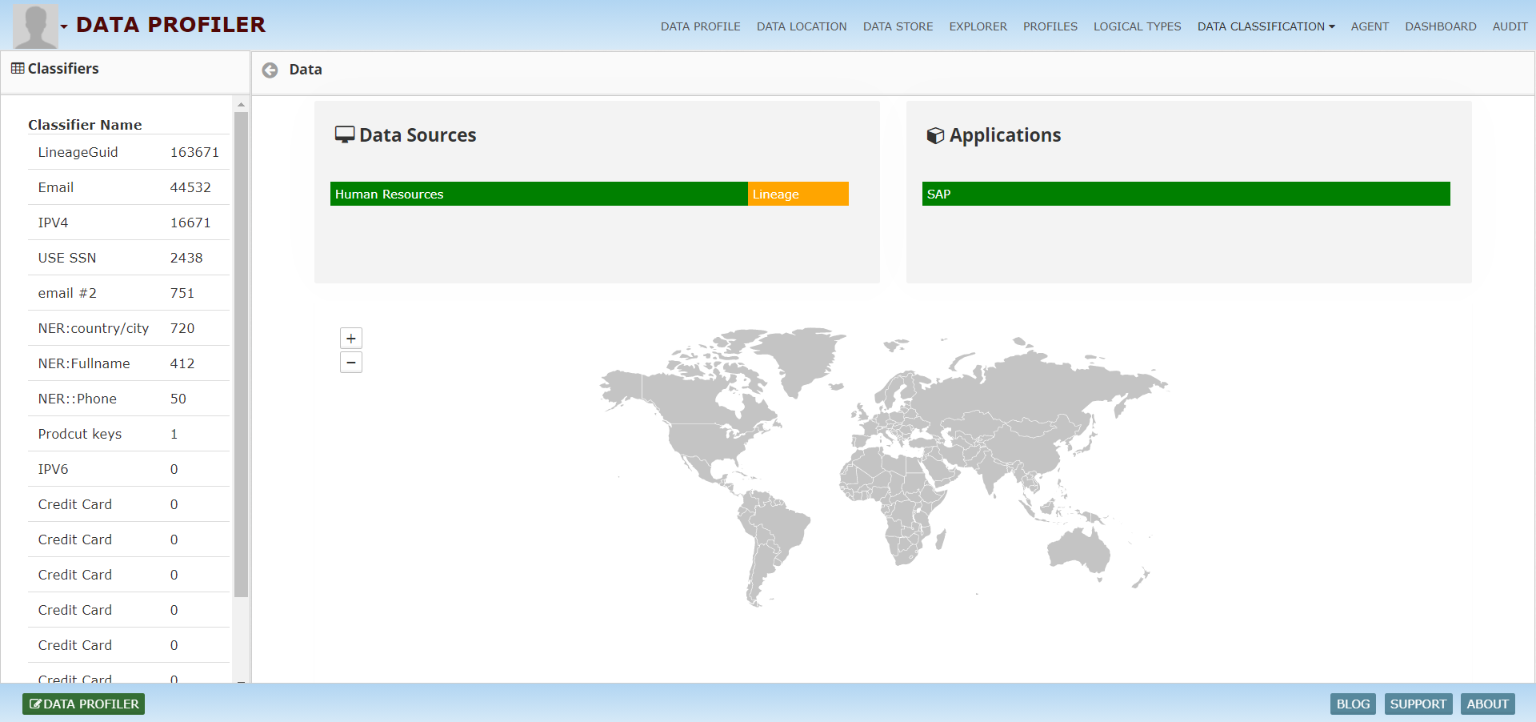
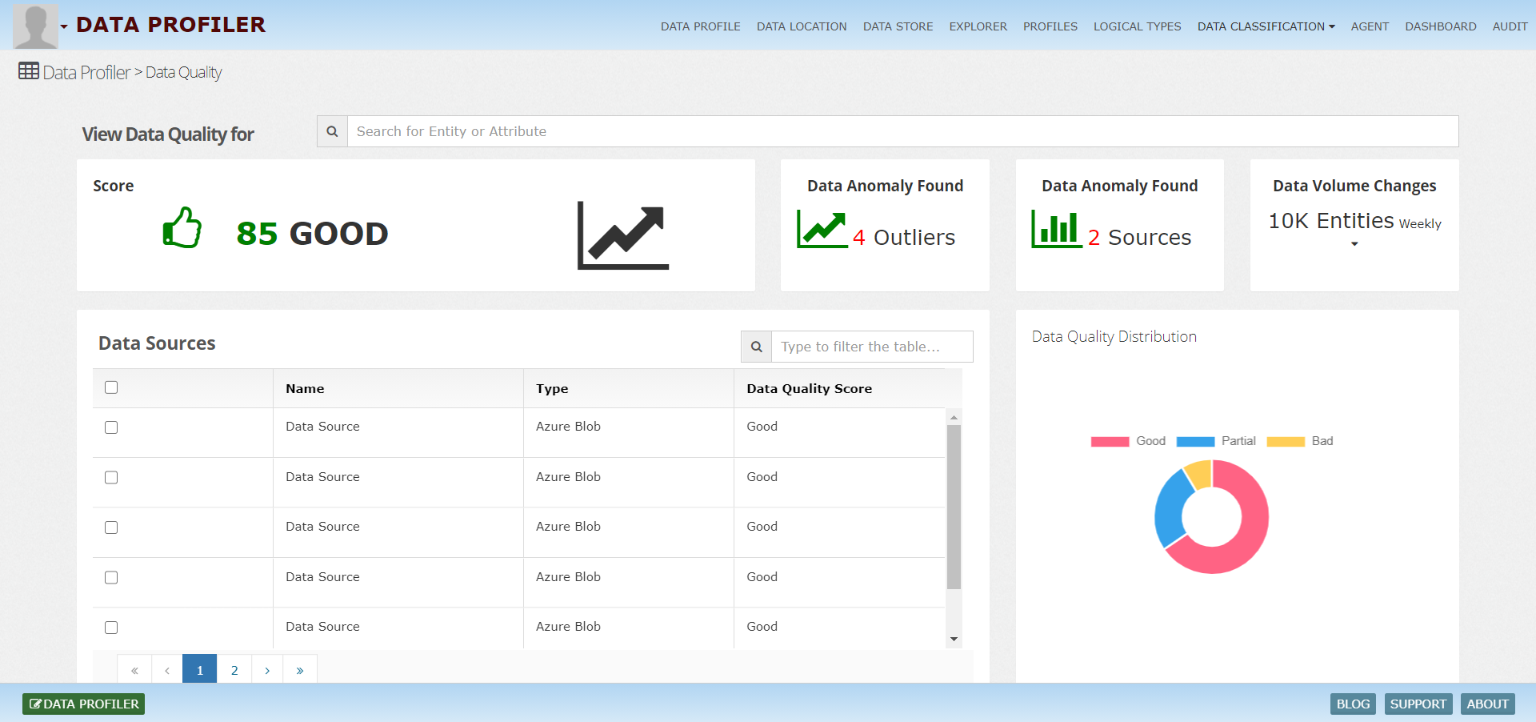
Actively monitor the consistency, accuracy, completeness and validity of your data with BigID – on all of your data sources in one single platform.
Insightlake takes a new machine learning based approach to personal data discovery that is focused on personal information – leveraging identity intelligence and machine learning to deliver an accurate and scalable method focused on personal and sensitive data in order to satisfy data privacy requirements at scale.