Traditional BI has been working for companies for some time now. Dumping daily changes at the end of the day to warehouse and generating reports for business worked. However as businesses become more and more nimble, access to real time changes become a key requirement. Understanding what is going on right now unlocks many opportunities for companies. Few examples below: Better manage customer churn Effective real time marketing Fraud prevention in real time Effective resource planning and utilization, reduces nightly batch load time from hours to minutes Live data marts (Hadoop Data Lake + CDC) can be created providing great insights However accessing real time activity could be very expensive (performance) and impact performance of operational databases.
Based on the use cases and criticality companies can use near real time or real time approaches. In case of near real time micro/mini batches can be performed at every minute or hour level. They can use change data capture to get real time changes from operational data bases.
Periodic SQOOP/JDBC Pull - Periodically makes connection with DB and based on audit columns pull change data. This method puts load on operational databases, should be used when performance impact is acceptable. CDC - Change data capture - Reads database change logs and provides changes. This method doesn't put too much load on the operational databases and very efficient.
InsightLake enables companies to collect real time changes effectively, transform/enrich and gain instant insights. It allows replication of tables between heterogeneous tables in relational and Big data environments. Solution works on premise and cloud seamlessly. In this article we will focus on how InsightLake Data Management solution could be used to implement both historical data pull and real time change data capture.


Oracle - Log miner/Log Reader Agent MySQL - Binary logs MongoDB SQL Server DB2, PostgreSQL etc.. Hadoop (Cloudera, Hortonworks, MapR, AWS) Kafka
All operations on the operational databases results in change. For example Insert, Update, Delete etc. Insight Lake CDC implementation captures the changes non intrusively and effectively making sure minimal impact on operational databases.


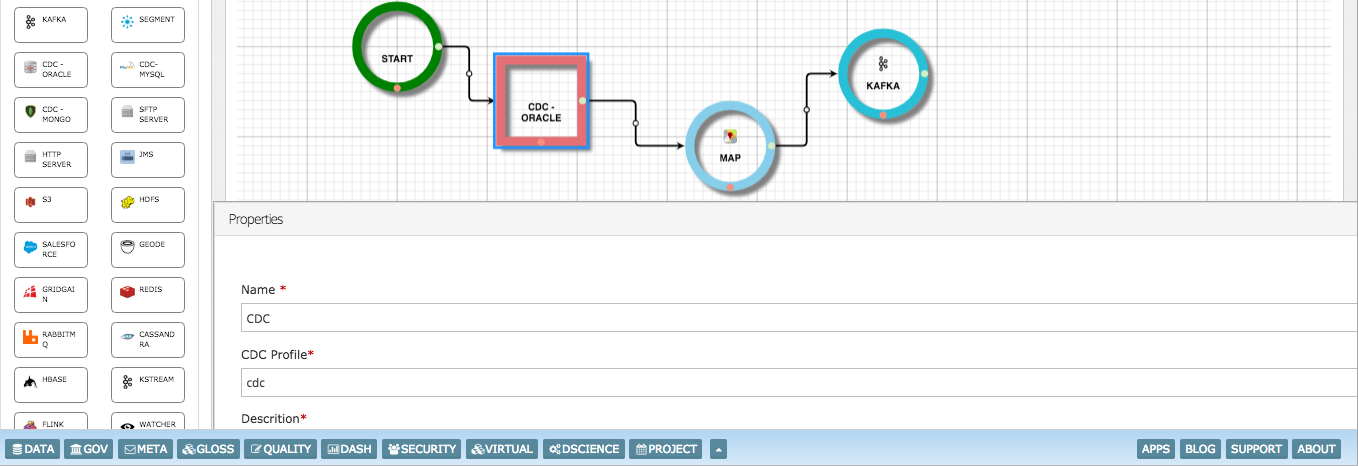
Build CDC pipelines to filter or enrich the change data before persisting on Kafka or Data Lake.
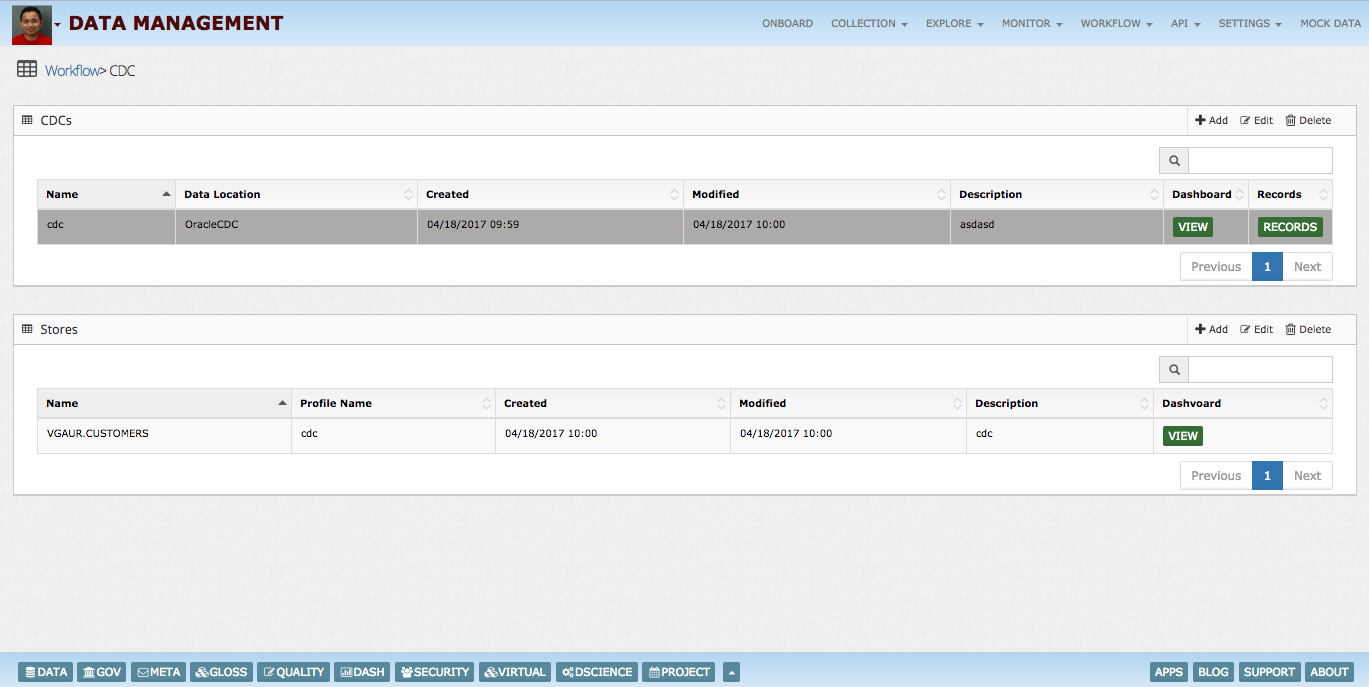
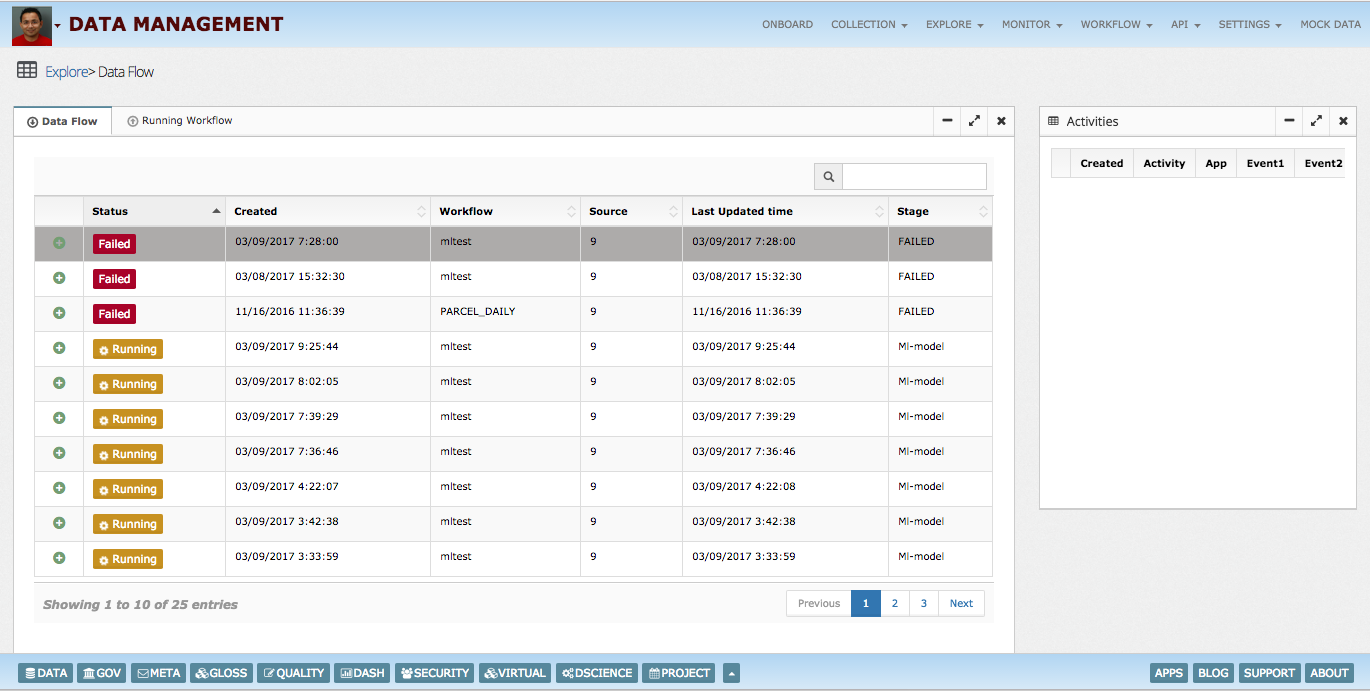
CDC dashboards provides insights into running pipelines and how changes are processed.

InsightLake CDC solution allows replication of tables from operational databases to Hadoop data lakes. Using the intuitive UI data teams can quickly select tables for which changes need to be captured or replicated. It also allows generation of target schemas. CDC solution handles change events in parallel at big data scale. Committed transactions changes can be captured Change events can be batched to improve ingestion performance Events can be posted to enterprise wide message brokers like Kafka
InsightLake uses non intrusive way with low footprint to capture change data using database logs.

Using InsightLake Data management solution historical data can be pulled and loaded to target data stores like Hadoop lake (Hive) or No-SQL data bases etc. Data can be pulled in parallel way utilizing power of multi-threading/Big Data scale from various source systems.
InsightLake intuitive UI allows creation of thousands of CDC pipelines for replication or change data capture. UI provides dashboards to monitor pipelines for their status and execution performance. SLAs and alerts can be configured for each pipeline.